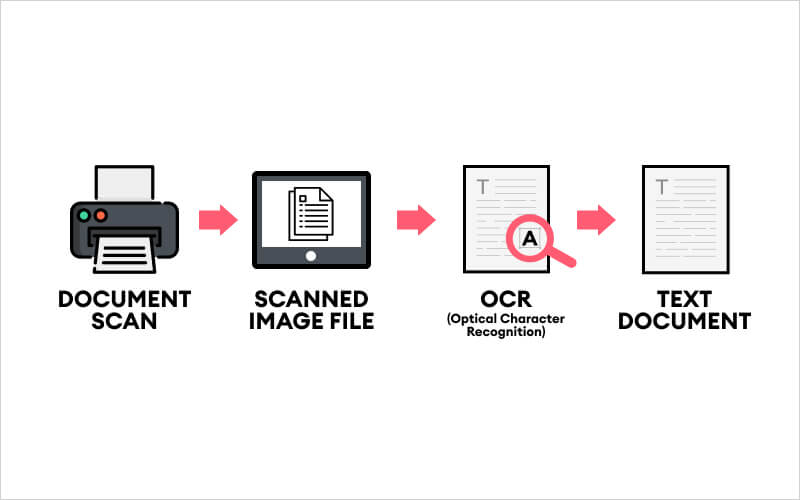
How OCR works is a fundamental question for anyone interested in the digital transformation of our modern paper-filled world. Every day, millions of people use Optical Character Recognition (OCR) technology to scan PDF documents, deposit bank checks via mobile apps, or translate foreign signs in real-time. Despite its ubiquity, the complex sequence of events that occurs when a computer “reads” a flat image remains a mystery to most. It often feels like magic when a static picture of a spreadsheet suddenly becomes an editable Excel file, but in reality, it is the result of a highly logical, multi-stage technological process.
To understand the core of this innovation, we must first define what is optical character recognition in professional terms. OCR is the mechanical or electronic conversion of images of typed, handwritten, or printed text into machine-encoded text. This technology acts as the essential bridge between the physical world of analog paper and the digital world of structured data. By learning exactly how OCR works, you can better appreciate the speed and precision it brings to business workflows, legal archives, and healthcare records.
The 4-Step Pipeline: How OCR Engines Transform Pixels into Data
The journey from a raw image file to a searchable digital document is complex. Professional OCR engines do not simply “look” at words; they break down images into millions of pixels and analyze them through a series of mathematical filters. We can categorize how OCR works into four distinct stages, each vital for ensuring 99.9% accuracy.
Step 1: Intelligent Image Pre-processing
The first and perhaps most critical step in understanding how OCR works is image pre-processing. Before the “reading” begins, the software must clean the visual “canvas.” Scanned documents are rarely perfect; they are often plagued by digital noise, dust specks, or poor contrast that can confuse an algorithm.
-
Despeckling: This process removes small digital dots and artifacts that might be mistaken for punctuation marks like periods or commas.
-
Binarization: The engine converts the colored or grayscale image into a high-contrast black-and-white (binary) map. This isolates the text (foreground) from the paper (background), allowing the algorithm to focus exclusively on character shapes.
-
Deskewing: Often, paper is scanned at a slight angle. The software automatically detects this tilt and rotates the image until the lines of text are perfectly horizontal. Straight lines are a prerequisite for high-accuracy segmentation.
Step 2: Sophisticated Segmentation
Once the image is clean and level, the software moves into segmentation. This stage is a vital part of how OCR works to organize chaotic visual data into a structured hierarchy. The computer cannot interpret an entire page at once; it must break it down into manageable chunks.
First, the layout analysis engine identifies blocks of text and separates them from non-text elements like logos, photos, or margin lines. Next, it breaks these blocks into individual lines, then words, and finally, isolated characters. This hierarchy mimics the way the human eye tracks text from left to right and top to bottom. Proper segmentation ensures that a word like “chart” is recognized as a single entity rather than a jumbled sequence of letters.
Step 3: Character Recognition Logic
Now we arrive at the intellectual heart of the process: the recognition phase. This is the stage that defines how OCR works at its most fundamental level. To identify that a specific shape is the letter ‘A’ or the number ‘8’, modern engines use two primary methodologies:
-
Pattern Matching (Matrix Matching): This is the traditional approach to what is optical character recognition. The computer compares each character pixel-by-pixel against an internal database of known fonts. If the scanned shape matches a stored template of “Times New Roman A,” it records an ‘A’. While effective for standard fonts, this method struggles with new styles or handwritten text.
-
Feature Extraction: This is the more advanced way of defining how OCR works. Instead of matching the whole image, the AI analyzes the “DNA” of the shape. It looks for lines, closed loops, intersections, and curves. It knows that an ‘H’ consists of two vertical lines with a horizontal crossbar. This allows the system to recognize fonts it has never seen before, making it the secret behind high-fidelity handwriting recognition.
Step 4: Linguistic Post-processing
The final step in the digital journey is post-processing, where the software acts as a professional editor to correct remaining errors. Even the most powerful AI can make mistakes during recognition. Post-processing is the crucial safeguard in how OCR works to ensure data integrity.
The system utilizes Lexical Analysis, comparing the extracted text against massive internal dictionaries. If the engine mistakenly reads “C0mputer” with a zero, the dictionary logic automatically corrects it to “Computer” based on linguistic probability. Furthermore, the engine assigns a “Confidence Score” to every word. If a word is too blurry to be certain, it is flagged for human review, ensuring that the final output reaches near-perfect accuracy.
The Evolution: Traditional Rule-Based OCR vs. Modern AI OCR

To fully grasp the current state of how OCR works, we must examine its historical evolution. The technology has moved from rigid, rule-bound systems to flexible, learning intelligences.
The Era of Rule-Based OCR
In the past, the answer to how OCR works was based entirely on strict templates. These “Rule-Based” systems required perfect conditions: clean paper, standard fonts, and high-resolution scans. If a document used a non-standard script or was slightly crumpled, the OCR would fail. This severely limited the practical applications of what is optical character recognition in the early digital age.
The Rise of Deep Learning and ICR
Today, we have entered the era of Intelligent Character Recognition (ICR). This represents a massive leap in how OCR works by utilizing Deep Neural Networks. Modern AI can learn from millions of examples, adapting to different handwriting styles and complex document layouts without manual programming.
Furthermore, the integration of Natural Language Processing (NLP) allows the software to understand the semantic context. If the AI sees a shape that could be either a “0” (zero) or an “O” (letter), it looks at the surrounding text. If it is surrounded by numbers, it chooses “0”; if it is in the middle of a word, it chooses “O”. This contextual awareness is the future of how OCR works, turning simple scanners into intelligent readers.
Why jpgtoexcelconverter.com is The Right Solution For You?
Understanding how OCR works is the first step toward optimizing your data workflow. At jpgtoexcelconverter.com, we take the complexity of this technology and make it accessible with a single click. Our platform utilizes the latest advancements in AI-driven OCR to ensure your images are transformed into perfect, editable Excel spreadsheets with unmatched precision.
We specialize in high-accuracy table recognition, ensuring that every cell and grid line from your physical document is preserved in the digital export. Whether you are a finance professional digitizing thousands of invoices or a researcher converting old records, jpgtoexcelconverter.com provides the speed, security, and accuracy you need. Stop retyping data manually and let our intelligent OCR engine handle the heavy lifting for you today.
Conclusion
The evolution of how OCR works has transformed one of the most tedious administrative tasks—manual data entry—into a lightning-fast digital process. By combining image pre-processing, intelligent segmentation, advanced feature extraction, and linguistic post-processing, OCR bridges the gap between physical paper and actionable data.
As AI continues to improve, the definition of what is optical character recognition will expand to include even deeper semantic understanding and perfect accuracy. Don’t let your data stay trapped in static images. Embrace the power of modern OCR technology and experience a more efficient, data-driven future with jpgtoexcelconverter.com. Try converting your first document now and see the magic of text recognition in action.


